
目录
简介
Huginn 是一个用于构建代理的系统,可以为您在线执行自动化任务。他们可以阅读网络、关注事件并代表您采取行动。Huginn 的代理创建和消费事件,沿着有向图传播它们。将其视为您自己服务器上的 IFTTT 或 Zapier 的可破解版本。您始终知道谁拥有您的数据。
项目主页:https://github.com/huginn/huginn
官方文档:https://github.com/huginn/huginn/blob/master/doc/docker/install.md
Huginn可以用来做什么?
- 将获得的数据进行相应的格式处理输出,例如RSS;
- 将获得的数据通过第三方接口(huginn官方支持不少)进行发出,例如发邮件;
- 将获得的数据作为相关参数用作另一事件event的参数,例如将获得的天气信息作为Email Agent的内容。
不难发现,通过以上三方面的组合操作,Huginn可玩性颇高,它不仅仅可以用来制作RSS源,是一款自动化的效率利器,你可以把它看作是自己服务器上的 IFTTT 或 Zapier (注:两款皆是自动化工具)的破解版本。解锁更多姿势,请参阅官方文档 。
安装
官方提供了很多种安装方式,本文教程采用了Docker的安装方式,Docker是一个轻量的实现虚拟化的利器,不用一个一个安装需要的应用,个人用足以,使用方法不详述了,有需要的朋友可以看下本文关于Docker的文章。
使用Docker启动你的 Huginn 容器:
docker run -it -p 3000:3000 huginn/huginn
在浏览器中打开 Huginn http://localhost:3000
默认:
登录用户名:admin
登录密码:password // 登录进去可自行修改使用
制作Agents
以下以制作“暮城自留地”的最新文章RSS为例
初始化已经有一些Agents,你可以从里中学习到一些使用方法。点击+ New Agent添加第一个Agent,Type选择Website Agent:
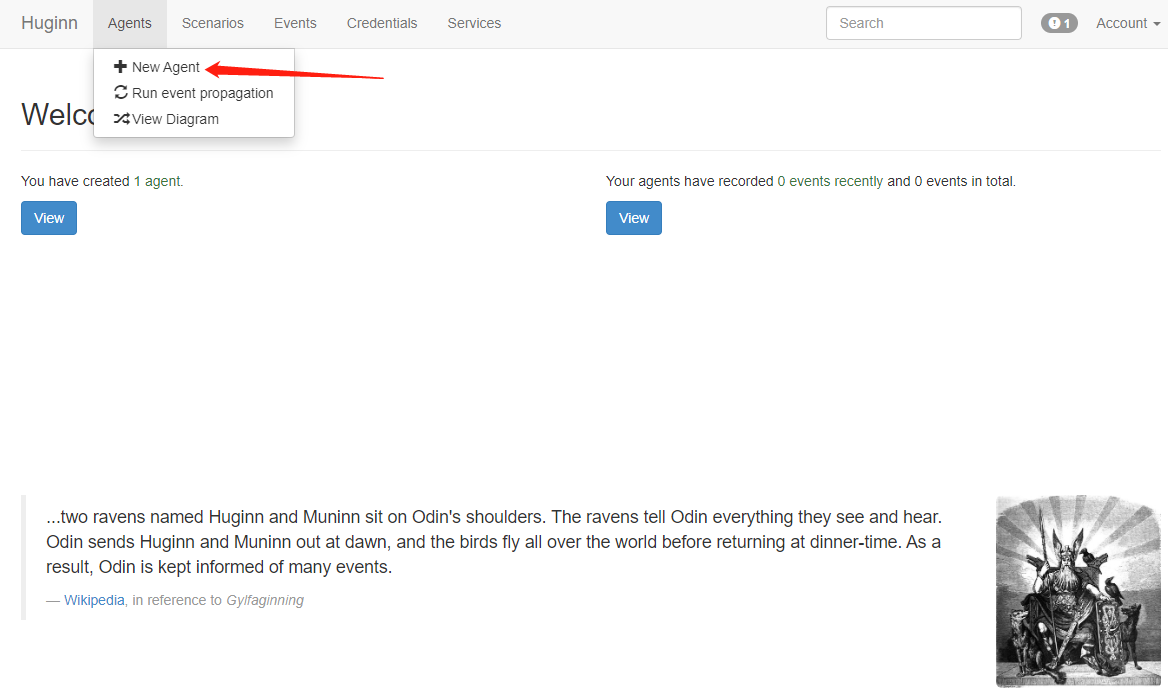
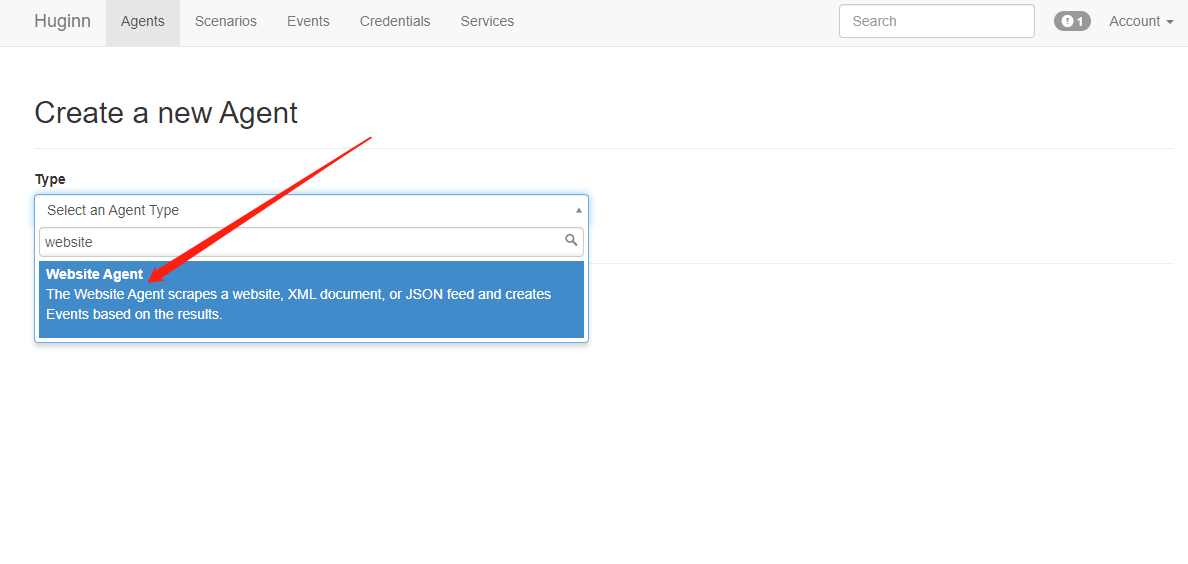
Name框输入名称,Schedule下拉框选择执行的间隔时间,其他默认即可
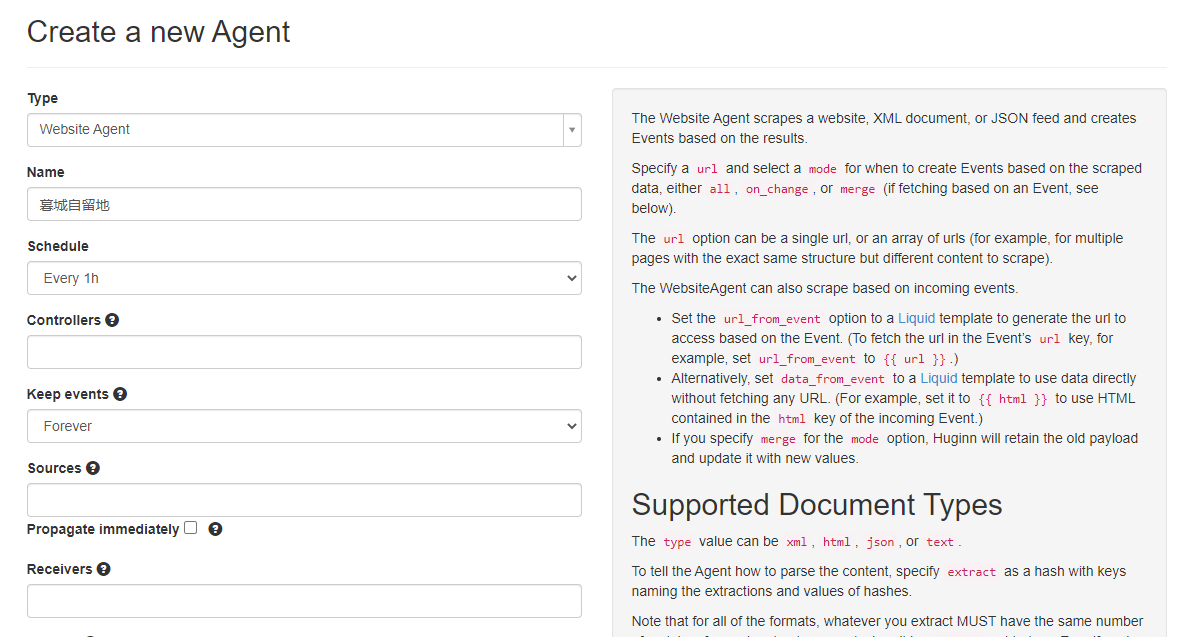
Options参数最为关键,右侧都有英文说明的,字段简要说明如下:
url:网址链接
type:返回的数据类型,支持xml,、html、json、text,此处填写html
mode:抓取模式,可选all, on_change, merge,这里填写on_change,表示页面有变化才会抓取
extra:表示抓取规则,
- url和title表示抓取字段的名称,可随意命名;(后面用得着,作为参数传给其他Agent)
- css表示抓取内容的css路径,value表示抓取的值,@href表示抓取对应css标签的href属性值,还有@src,@title等等;
- 如果要抓取对应标签的值,可填
.(包括html代码的全部内容),string(.)(只包含对应标签的值),text()等同string(.)
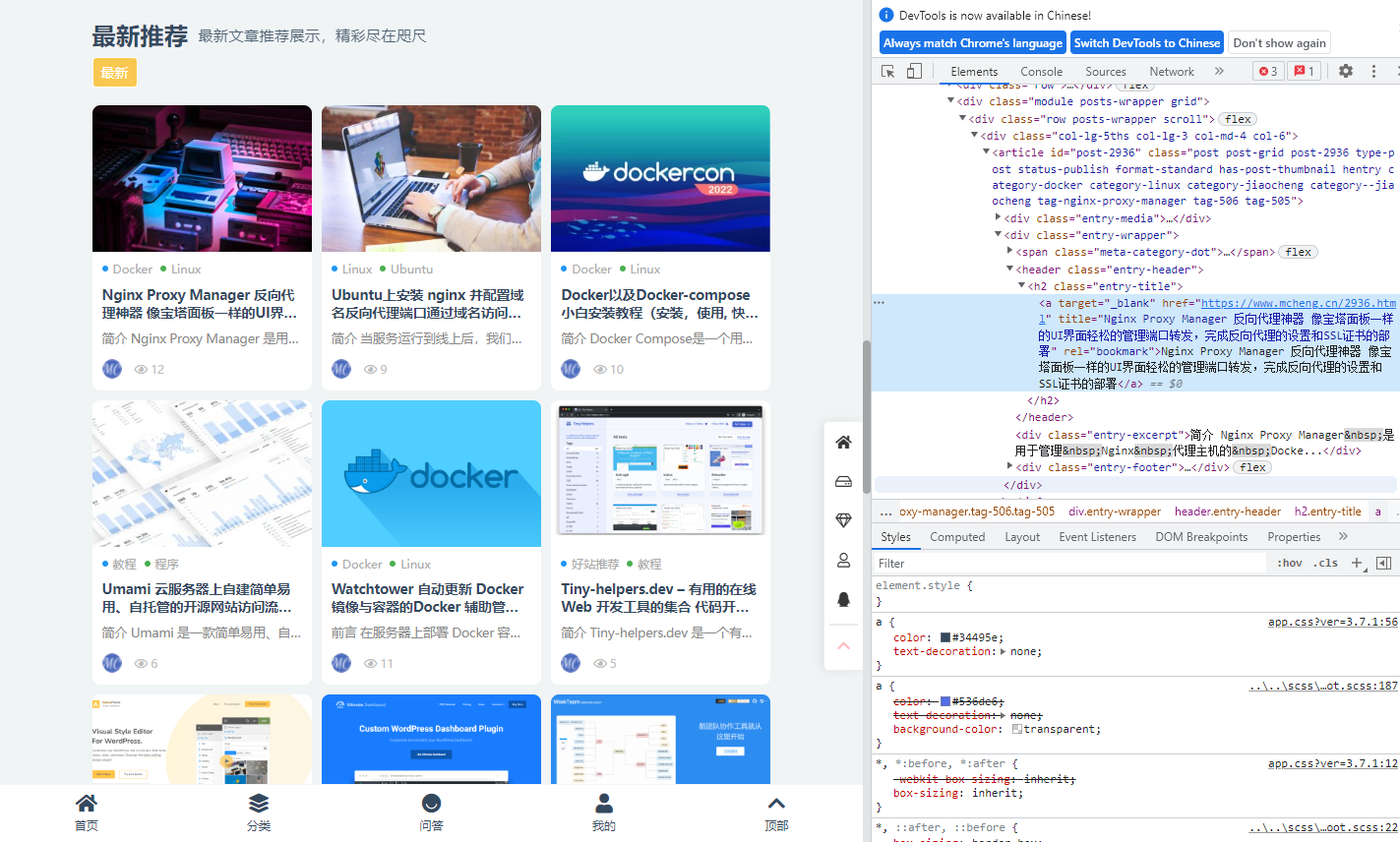
接下来需要配置采集地址 url,即 暮城自留地 首页的网址;第一个帖子的 css 定位,可以通过 f12 查看帖子的 xpath,下图所示:
自定义代码如下:
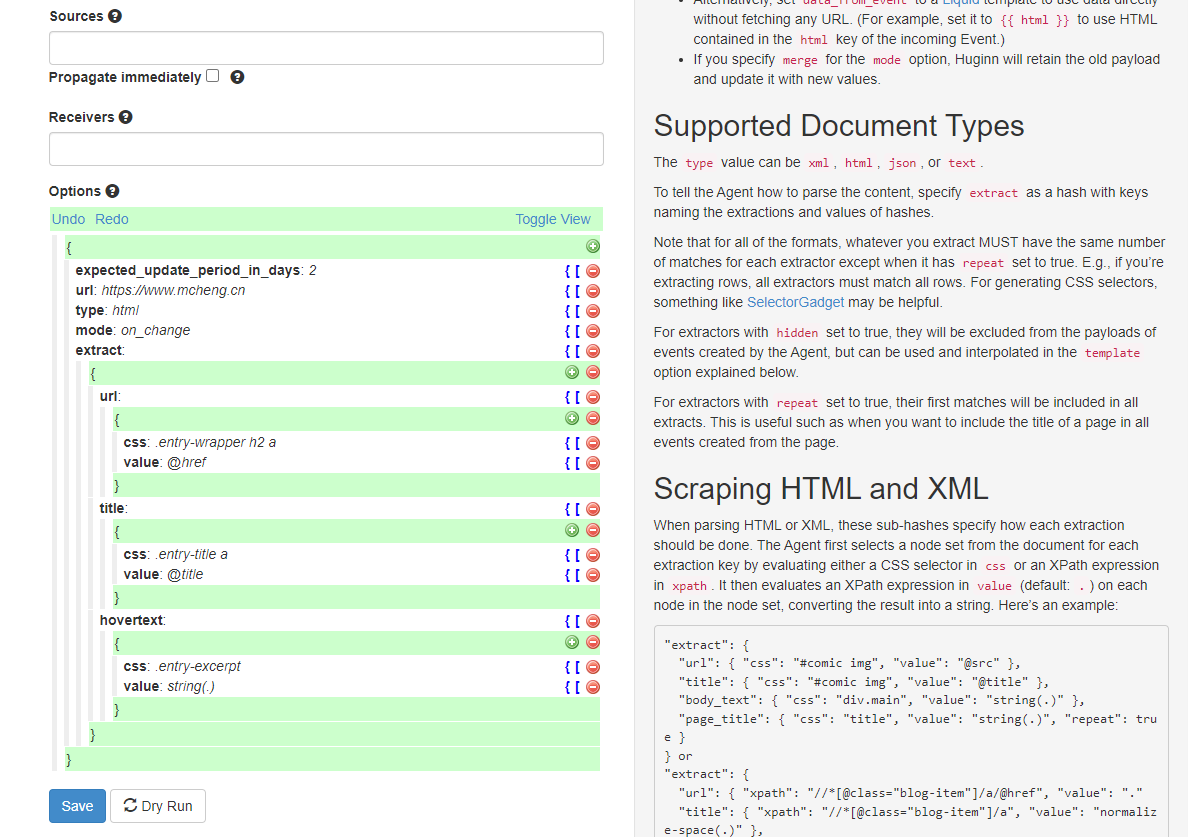
{
"expected_update_period_in_days": "2",
"url": "https://www.886699.xyz",
"type": "html",
"mode": "on_change",
"extract": {
"url": {
"css": ".entry-wrapper h2 a",
"value": "@href"
},
"title": {
"css": ".entry-title a",
"value": "@title"
},
"hovertext": {
"css": ".entry-excerpt",
"value": "string(.)"
}
}
}
点击 Dry Run 试运行,查看效果:
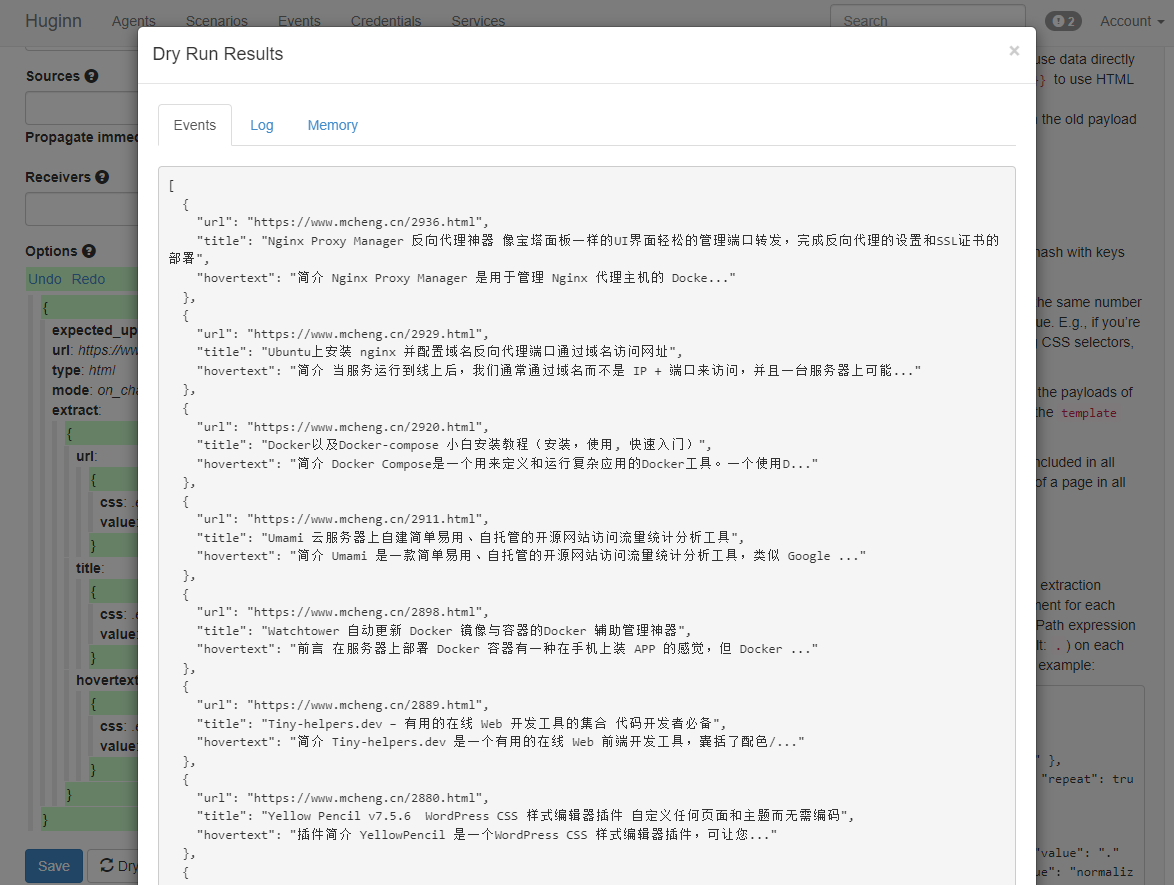
如上图显示抓取到了数据表明有效,然后点击save保存,否则请修改extract下的参数再试。
保存后run一下,然后就会有生产出很多events,就是获取到的数据。如果没有获取到可能是数据库的问题。
试运行没问题的情况下,如果在正式运行时提示:/app/app/models/agent_log.rb:16:in `write',则重启一下容器即可。
小技巧:
如果使用xpath的时候,复制复制的东西如下:/html/body/div[1]/div/div/ul/li[1]/h2/a/span/text(),但是还有两个问题,一个是,我们只爬了一个标题,二是标题有空格,这个时候我们可以优化一下:把我们的 xpath 改成这样。/html/body/div[1]/div/div/ul/li/h2/a/span/text()是因为 li[1] 代表我们第一个标题,所以把[1]去了就可以了,然后 “value”: “normalize-space(.)” 这句话的意思就是把空格去了。
到了这里,可以进行第三步直接输出XML订阅地址,因为RSS阅读器都有获取全文功能,我们把url1这个网址告诉RSS阅读器,阅读器会自动加载出全文,如果阅读器获取的全文排版很乱,我们才会做第二步,就是用Huginn获取全文,再输出XML订阅添加到阅读器里。
推荐feedburner:https://feedburner.google.com/
获取全文输出
同样的,Type选择Website Agent,Sources选中第一个Agent,下面的框 Propagate immediately 一定勾选上:
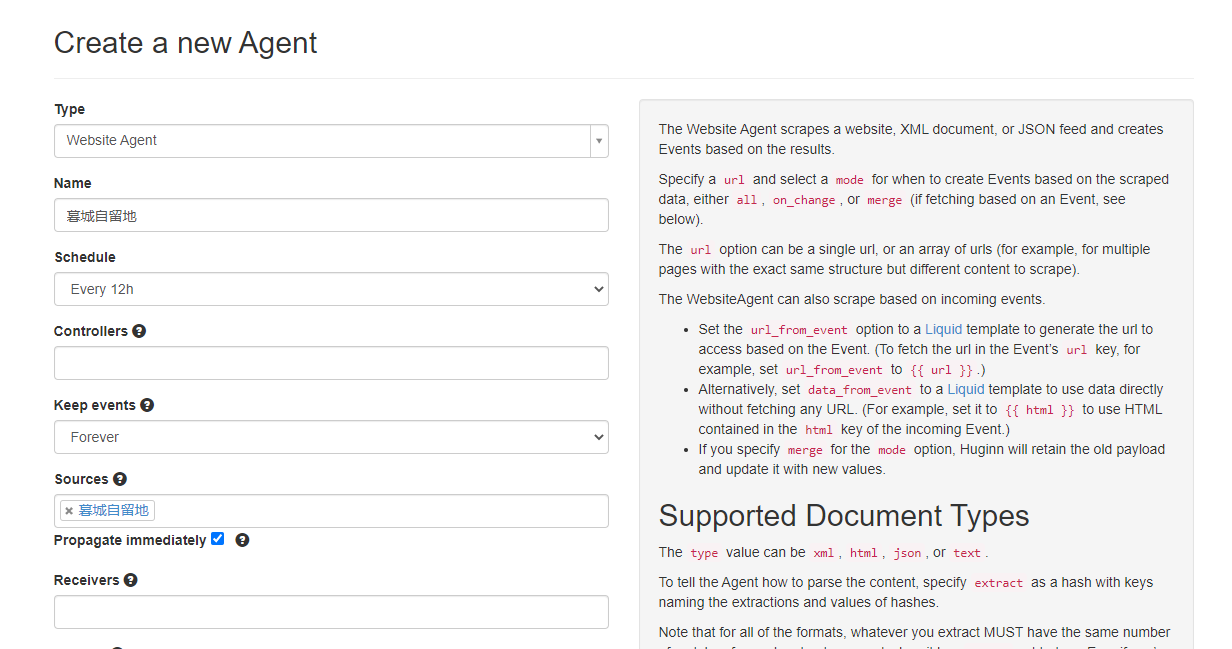
然后在选项设置处,URL填写:{{url}},即抓取你刚刚获取RSS的链接地址,mode选择“merge”,CSS 就是本文的css ,value填入“normalize-space(.)”,即原样输出全文并合并原先的输出。,这样两个Agent的字段就组合到一起了,同样的选择一个接受到的event测试一下,然后点击保存即可。然后返回页面把第一个的events都删除:
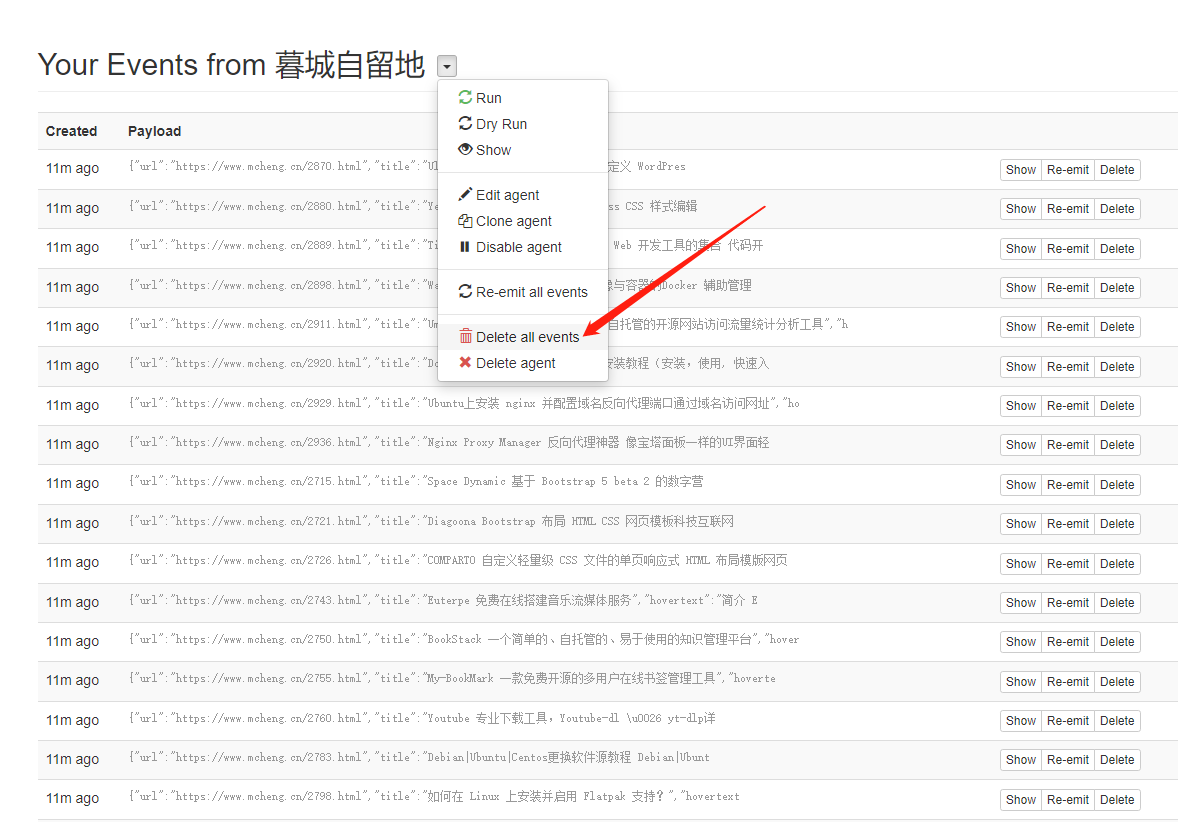
重新run一下可以发现第二个Agent也自动执行了,第二步完毕。
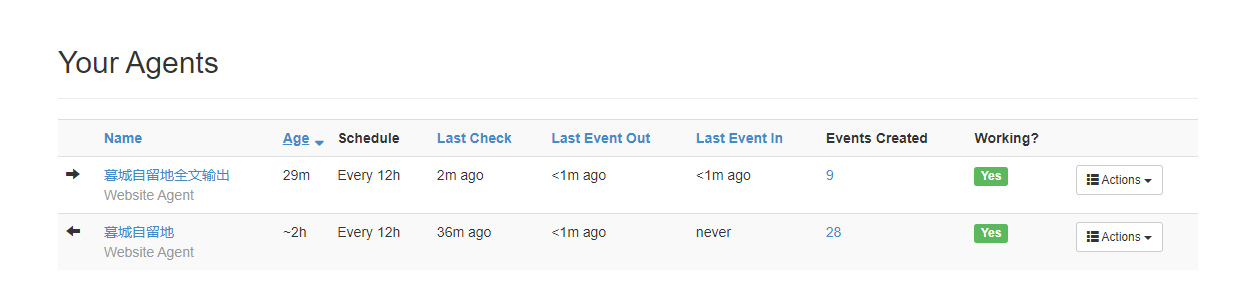
输出成RSS
点击新建Agent,类型选择Data Output Agent,Sources中填入第二步的Agent名称:
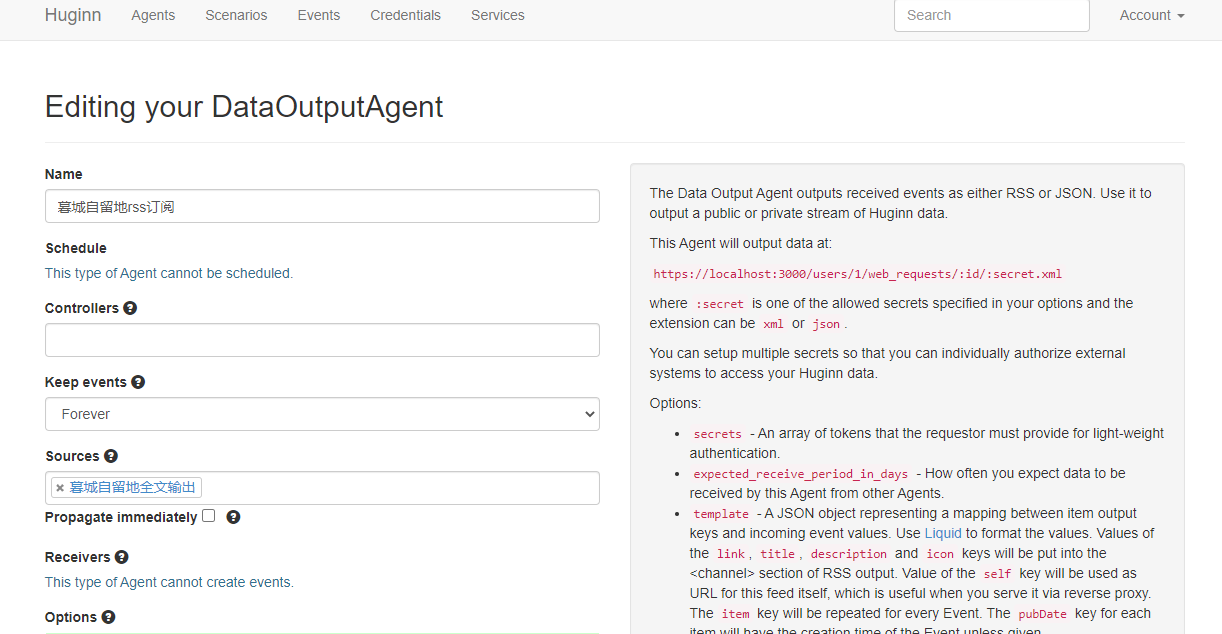
在选项中填入你的RSS的标题、描述、链接等信息,同时在Item中填写标题、描述、链接等,即输出RSS全文的标题、内容与链接地址等等:
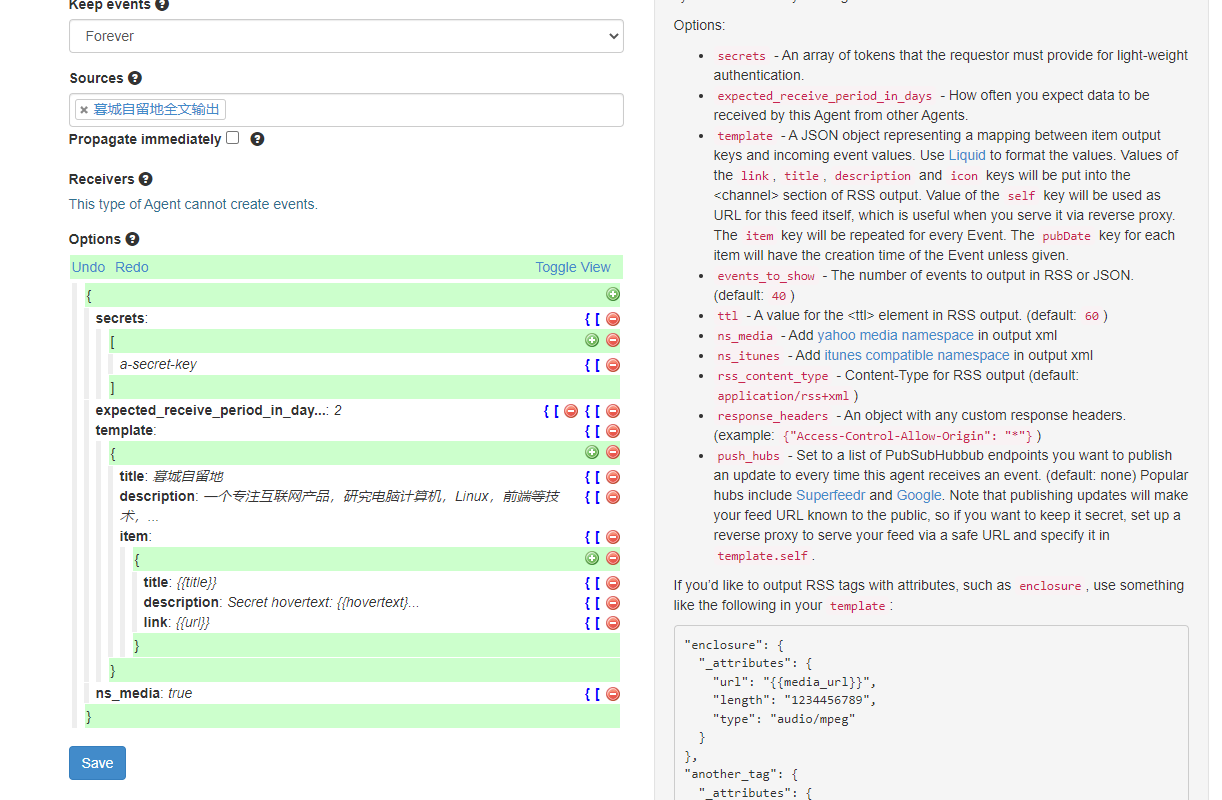
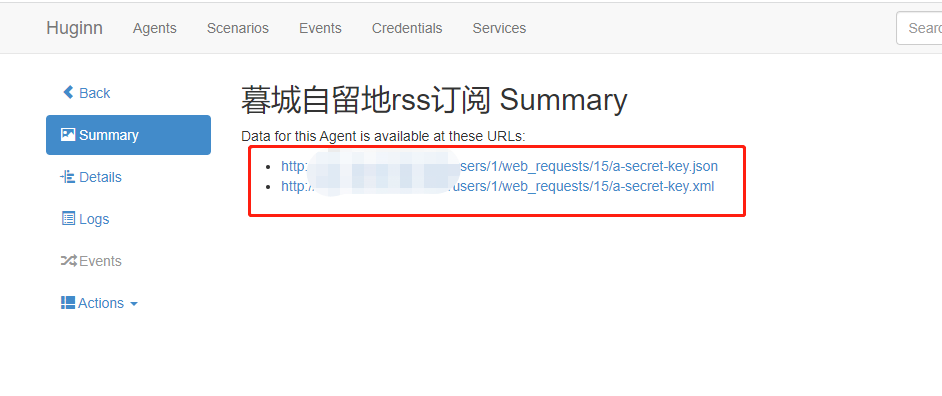
进阶
options的具体介绍
Website Agent可以爬取来自url/url_from_event/data_from_event的信息。
type
可以xml, html, json, or text。相应的类型有各自的介绍,这里是HTML网页,就用html好了。
可以是all, on_change, or merge。If you specify merge for the mode option, Huginn will retain the old payload and update it with new values.
即如果选择merge,则会与之前的信息合并,这个在获取教务通知的具体内容时会用到,之后不再赘述。这里只需要在出现新通知的时候触发,所以用on_change。
extract里就是要解析的内容,可以用a CSS selector in css or an XPath expression in xpath. (如果type里选text则可以用regexp正则匹配,然而如果要html提取后再正则匹配就需要再来一个Agent,感觉有点蠢emmm如果有更好的办法欢迎来和我交流一下哈)
- 要注意的是:这个解析的内容是根据url浏览后直接获得的页面,没有加载文本之外的任何内容,没有经过JavaScript渲染等等。或者说就是你
F12在Network里看到的页面加载出来的document或xhr之类得到的response。(这个是在利用 Huginn 爬取其他网站的时候发现的) - 如果需要爬取JavaScript加载的网页,可以使用 Phantom Js Cloud Agent,这个需要在PhantomJs Cloud申请一个API,有一定的免费额度。这个Agent会返回页面的相应信息,还可以具体设置输出JSON、截图等等。
extract里以JSON格式写要解析的对象,后面就会返回 相应名字作为Key,相应的值作为Value 的JSON结果。
CSS可以这样找↓,譬如直接复制CSS路径,再进行缩略处理:
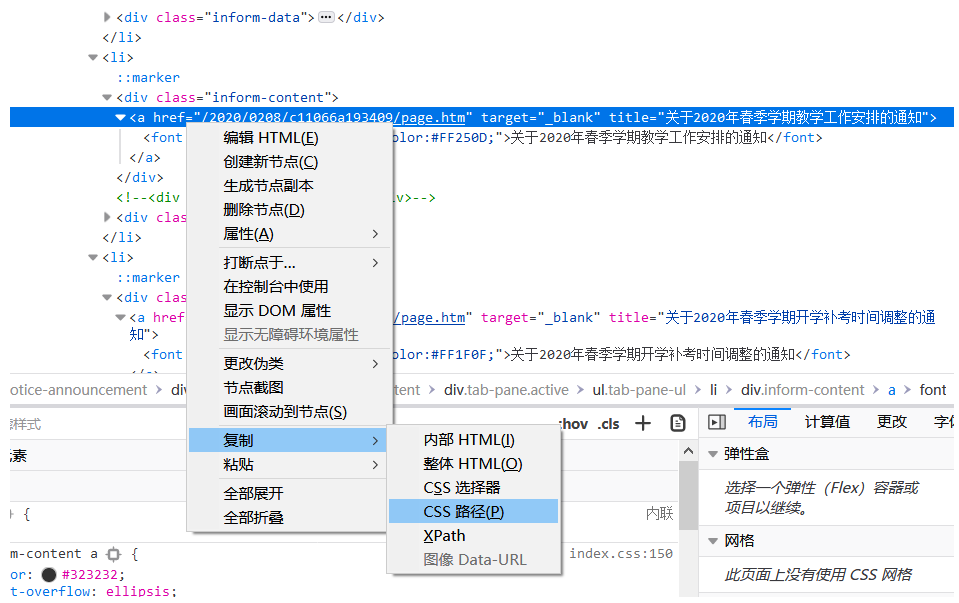
比如这里复制出来是复制成功css
html body div.container-fluid div.main-content.clearfix div.left-content div.notice-announcement div#index_notice_content.tab-content div.tab-pane.active ul.tab-pane-ul li div.inform-content a然后处理 css path:
原始路径过长,删去不带 . 或 # 的节点(节点间以空格“ ”分割),并删去每个节点在 . 或 #前的第一个标签,得到:复制成功css
.container-fluid .main-content.clearfix .left-content .notice-announcement #index_notice_content.tab-content .tab-pane.active .tab-pane-ul .inform-content a前半部分对节点定位用处不大,继续缩略,于是得到复制成功css
.tab-pane.active .tab-pane-ul .inform-content a非常规情况处理:
a. 有些路径中的节点带空格,如<div class="packery-item article">,路径中的空格由.代替,截取为.packery-item.article
b. 当抓取多种 css path 规则时,用逗号,分割css
"css": ".focus-title .current a , .stress h2 a",value用来提取标签中的属性,可以利用XPath functions。(中文介绍)
Xpath Functions是可以进行嵌套来用的
这里用了 @href来提取链接,用string(.)来提取这个css路径下的字符串,用 normalize-space函数来去除多余的空格。得到的JSON表达式如下:
"extract": {
"url": {
"css": ".tab-pane.active .tab-pane-ul .inform-content a",
"value": "@href"
},
"title": {
"css": ".tab-pane.active .tab-pane-ul .inform-content a",
"value": "normalize-space(string(.))"
}
}
template
除了上面这些,还可以设置User Agent,以及一个用**Liquid模板语言编写的模板template**等等。
Liquid markup language. Safe, customer facing template language for flexible web apps.
Liquid官方仓库:https://github.com/Shopify/liquid。这里有关于Liquid语法的中文介绍:https://liquid.bootcss.com/。
Liquid也是可以嵌套的,利用管道 | 可以将处理后的结果送到下一个filter:

在这里,由于得到的 href 是相对地址(如 /2020/0208/c11066a193409/page.htm),为了得到绝对地址,在template中利用 {{ url | to_uri: _response_.url }} 进行处理。
(别说了,这几天找遍了XPath function和Liquid用法)
设好之后可以点击Dry Run来试试,看看运行的结果,再做进一步的修改。
于是最终得到的Crawler_AAO #1 Get Notice URLs Options 如下:
{
"expected_update_period_in_days": "2",
"user_agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:72.0) Gecko/20100101 Firefox/72.0",
"url": "http://aao.nuaa.edu.cn/",
"type": "html",
"mode": "on_change",
"extract": {
"url": {
"css": ".tab-pane.active .tab-pane-ul .inform-content a",
"value": "@href"
},
"title": {
"css": ".tab-pane.active .tab-pane-ul .inform-content a",
"value": "normalize-space(string(.))"
},
"time": {
"css": ".tab-pane.active .tab-pane-ul .inform-data",
"value": "normalize-space(.)"
}
},
"template": {
"url": "{{ url | to_uri: _response_.url }}"
}
}